深度强化学习笔记(数学基础)
基本概念
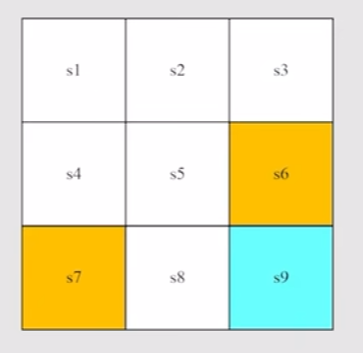
以这个grid world作为例子,这是一个3*3的网格,我们需要让agent做出正确的决策,使得其能够到达右下角的s9。需要注意的是s6和s7是两个禁区,进入这两个区域会受到一定的惩罚。强化学习的概念就是需要agent根据当前的环境(Environment)做出正确的决策,使得达到一定的目的。
状态State
agent需要理解当前的环境,才能做出决策,所以这里环境就被用数学描述为状态。在这个例子中,由于环境的其他因素不会改变,所以可以只使用agent目前的位置来表示状态:
动作Action
agent根据环境做出决策即是动作,这个例子中动作有五个,分别是{向上,向右,向下,向左,原地不动},像这样的集合也可以用数学语言描述为
状态转移
当agent做出动作时,会对环境造成一定影响,当下一帧到来时,状态就会发生改变。例如,当在s1向右走一步时,就会出现如下式的状态转移:
当然,这个例子中是十分理想的情况,在很多情况下,下一步的状态是不确定的,比如在游戏中的一个敌人有75%的概率向右移动,25的概率向左移动,这时上述的表达便会有缺陷。像不确定的这种情况,通常使用更一般的分布来表达:
解释一下上面的式子,实际上就是条件概率,第一个式子的意义的在状态s1下做出动作a1,转移到s2的概率是0.8,第二个式子的意义是在状态s1下做出动作a1,转移到s1的概率是0.2。
决策
决策可以看一个条件概率,它给出了在一定的状态下做出各种动作的分布,使用数学语言表达为:
在一些场合下,面对一个状态做出的决策是肯定的,但是在更一般的情况下,决策会给出一个概率分布,agent会在一个均匀的区间采用,来依概率决定选择哪个动作来执行。
奖励Reward
奖励是人为给agent的指导,如果希望agent做某件事,那么就给予它正的reward,反之就给予负的reward。一般来说,t时刻的reward是根据t时刻的状态、动作和t+1时刻的状态要给出的,但是由于t+1时刻的状态在一定程度上取决于t时刻的状态和动作,所以我们可以像上文一样使用条件概率来描述reward:
回报Return
回报是指在当前状态能够获得的奖励的总和,这个值通常用来描述一个策略的好坏,最朴素且直观的计算return的方法就是将奖励累加:
如果状态数量无限多,那么这个无穷级数很有可能是发散的;同时,我们通常希望离当且阶段更近的奖励影响更大,即在当前时刻,应该更多考虑接下来几步的奖励,而非几万步后的几步。所以, 引入折扣回报(Discounted Return)的概念,在之后的每一项中加入一个折扣率,每多走一步,折扣率就要增幂。
这个公式也可以合并地写成:
马尔可夫决策过程
马尔可夫决策过程的几个关键点:
- 集合
- 状态集合
- 动作集合
- 奖励集合、
- 概率分布
- 由当前状态和动作决定的下一个状态的概率分布
- 由当前状态和动作决定的奖励的概率分布
- 策略:在当前阶段所生成的动作的概率分布
- 马尔可夫性质:无记忆性(下一个状态只与当前状态有关,与之前状态无关)
贝尔曼公式
状态价值State Value
上面所提到的Return,通常指的是一条路径所带来的的回报,回忆一下决策,它是一个概率分布,所以通常给出的路径不止一条。所以就提出了状态价值(State Value),用符号来表达。状态价值是回报的数学期望,其定义如下:
需要注意以下几点:
- 状态价值是关于状态s的函数,对于每一个状态都有一个状态价值;
- 状态价值与策略有关,所以其下标带有一个;
贝尔曼公式的推导
根据上述(3)(4)式,有:
\begin{align} v_{\pi}(s) = & E[G_t|S_t=s]\\= &E[R_{t+1}+\gamma G_{t+1}|S_t=s]\\=&E[R_{t+1}|S_t=s]+\gamma E[G_{t+1}|S_t=s] \end{align}
于是我们将状态价值表达为两个期望,首先我们分析第一项:
\begin{align} E[R_{t+1}|S_t=s]& = \sum_a \pi(a|s)E[R_{t+1}|S_t=s,A_t=a]\\ &= \sum_a\pi(a|s)\sum_rp(r|s,a)r \end{align}
这一项称之为Immediate Reward,它的意义是从s这个状态出发,到下一个状态的平均回报。
接下来是第二项:
从第一步到第二步,利用的是马尔可夫性质,即下一个状态仅与当前的状态有关,与历史无关;第二步到第三步是用状态价值函数的定义;第三步到第四步利用的是全概率公式。
纵观这个公式,我们将第一项称为Immediate Reward,第二项称为future Reward,贝尔曼公式将在s状态下的预期回报分解为下一步预期获得的回报和将来预期获得的回报。提取公因式后的贝尔曼表达式如下图所示,此等式将会出现在动作价值公式的推导中。

贝尔曼公式的向量形式以及求解
对于每个状态s,我们都可以写出形如上式的贝尔曼公式,于是,引出贝尔曼公式的向量形式:
是状态转移矩阵,其形式如下图所示,需要注意行与列的含义

求解
有解有两种方法,一种是解析解法,经过线性代数的移项可以求出状态价值的表达式为:
这个方法在状态数较多时求解较为复杂,因为矩阵求逆的过程需要花费很多的时间复杂度,更多情况下我们使用迭代法:
这个解法很像马尔可夫链的迭代求稳态,我们可以随机生成一个初始向量,不论其值是多少,都可以证明在迭代轮次足够多的情况下,。
动作价值Action Value
动作价值的定义是从一个状态出发,采取特定的行动后所得回报的期望。比较状态价值与动作价值之间的差异,可以发现,状态价值可以看成是对动作价值的各个动作求期望。其定义如下:
可以发现,动作价值的值不仅依赖于当前状态s和采取的动作a,还取决于采取的策略。上面提到,状态价值是动作价值的期望,所以有以下公式成立:
再观察下面这个移项之后的公式,将其与上式对比,可以发现,实际上方括号内的项就是动作价值的表达式。
所以动作价值的表达式又可以写成:
观察这个式子,发现其与贝尔曼方程有几分相似,其第一项也是短期回报,第二项也是长期回报的预期。所以,
贝尔曼最优公式
最优策略
定义1:当对于任意的,都有,那么我们称策略优于策略。
定义2:当策略优于其他所有策略时,我们称其为最优策略。
贝尔曼最优公式
贝尔曼最优公式其实就是在贝尔曼公式前加上一个优化条件,希望找出一个最优的策略,使得在各个状态下的状态价值达到最大。其矩阵形式为:
求解贝尔曼最优方程
我们以贝尔曼最优方程的矩阵形式来求解,设一个函数为:
那么贝尔曼最优方程就可以变成:
由压缩映射定理(证明略)可知,贝尔曼最优公式可以通过迭代求值来求解。
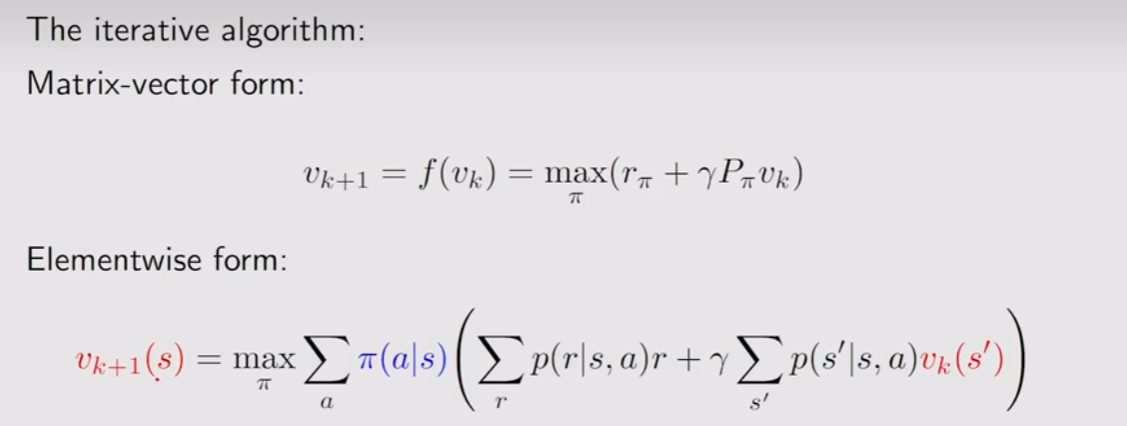

这个算法的过程和之前提到的迭代很相似,都是先估计一个大致的状态价值,然后计算出相应的所有,于是就可以利用上面这个的公式来最大化这个动作价值,最后求出。