一、绪论
数值计算算法设计的基本原则
- 要有数值稳定性,能够控制舍入误差的传播;
- 防止较小的数加到较大的数;
- 避免两个相近的近似值相减;
- 除法运算时,要避免除数的绝对值远远小于被除数的绝对值。
误差、有效数字
- 绝对误差:e=x∗−x,精确值减去近似值;
- 相对误差:er=xe=x∗x∗−x;
- 绝对误差限:∣e∣≤ϵ。
有效数字:

上述(1)描述如何从绝对误差限推导有效数字,(2)描述从有效数字推导绝对误差。
绝对误差限一般为0.5×10n,从第一个非零位到0.5之前那一位的数字个数就是有效位数。
绝对误差与函数:
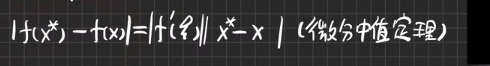
误差的计算方法
ϵ(x±y)=ϵ(x)+ϵ(y)ϵ(xy)=∣x∣ϵ(y)+∣y∣ϵ(x)ϵ(yx)=y2∣x∣ϵ(y)+∣y∣ϵ(x)ϵr(a±b)=∣a±b∣ϵ(a)+ϵ(b)ϵr(ab)≈ϵr(a)+ϵr(b)ϵr(ba)≈ϵr(a)+ϵr(b)
衡量数值计算算法优劣的标准
- 可靠的理论基础:正确性、收敛性、数值稳定性,是否可作误差分析;
- 良好的计算复杂性:包括计算量和所占的内存空间。
二、线性方程组
范数
范数的性质:幺元、线性、三角不等式
常见的向量范数:
∣∣x∣∣1=i=1∑n∣xi∣∣∣x∣∣2=i=1∑nxi2∣∣x∣∣∞=1≤i≤nmax∣xi∣
相容范数:若对任意矩阵A∈Rn×n,
∣∣A∣∣=∣∣x∣∣=1max∣∣Ax∣∣
则由上式定义的∣∣⋅∣∣是一种矩阵范数,其与所给定的向量范数相容,也称其为算子范数。
常见的矩阵范数:
列范数∣∣A∣∣1=1≤j≤nmaxi=1∑n∣aij∣谱范数∣∣A∣∣2=λmax(ATA)行范数∣∣A∣∣∞=1≤i≤nmaxj=1∑n∣aij∣F范数/欧几里得范数∣∣A∣∣F=∑aij2
矩阵的谱半径:
ρ(G)=i≤i≤nmax∣λi∣
高斯消去法
能进行高斯消去的条件:前n−1个顺序主子式的行列式不为0。(第i个顺序主子式:左上角的i×i元素构成的行列式)。
列主元高斯消去法
每次在消去前,将aik(k)中绝对值最大的那一行换到第k行。
迭代法
Ax=bA=N−PNx=Px+bx=N−1Px+N−1b
收敛定理:对于迭代形式x=Gx+d,收敛的充分必要条件是ρ(G)<1,充分条件是∣∣G∣∣<1。
ρ(G)<∣∣G∣∣
迭代法的误差
∣∣x(k)−x∗∣∣≤1−∣∣G∣∣∣∣G∣∣k∣∣x(1)−x0∣∣∣∣x(k)−x∗∣∣≤1−∣∣G∣∣∣∣G∣∣∣∣x(k)−x(k−1)∣∣
Jacobi迭代法
将矩阵A分解为A=D+L+U,则
x(k+1)=−D−1(L+U)x(k)+D−1b
收敛条件:
- 充要条件:ρ(G)<1
- 充分条件∣∣G∣∣<1
- 充分条件:矩阵A是主对角占优矩阵(主对角线绝对值比此列绝对值之和更大)。

Gauss-Seidel迭代法
令A=D+L+U,将U右移:
x(k+1)=−(D+L)−1Uxk+(D+L)−1b
实际上,为了避免计算(D+L)−1,通常采用:
x(k+1)=−D−1Lx(k+1)−D−1Ux(k)+D−1b
收敛条件除了Jacobi方法相同的部分外,还加一条:系数A是正定的(特征值大于0)。
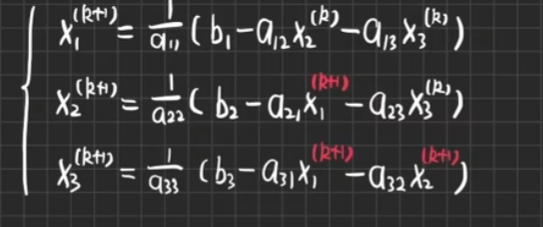
三、特征值
幂法求特征值
简单迭代:uk=Aku。
为了避免特征向量模过大,通常需要归一化:
{yk−1=∣∣uk−1∣∣uk−1uk=Ayk−1
范数取二范数
β=yk−1Tuk=yk−1TAyk−1k→∞limβk=∣∣α1x1T∣∣α1x1TA∣∣α1x1∣∣α1x1=∣∣α1x1∣∣22α12x1Tx1λ1=λ1
⎩⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎧ηk−1=uk−1Tuk−1yk−1=ηk−1uk−1uk=Ayk−1βk=yk−1Tuk
范数取无穷范数
⎩⎪⎪⎪⎨⎪⎪⎪⎧yk−1=∣∣uk−1∣∣uk−1uk=Ayk−1β=erTyk−1erTuk
反幂法
Axi=λixiA−1xi=λi1xi
原点偏移
Ax=λx(A−pI)x=(λ−p)x
则可求出∣λi−p∣最大的那个特征值。
幂法和反幂法的局限性
迭代是否收敛依赖于特征值的分布情况,不适合自动计算,只有矩阵阶数很高,无其他可用方法时,才用幂法和反幂法。
四、非线性方程求解
二分法
误差限ϵ=2bk−ak。
简单迭代法
收敛条件(需要两者都满足):
- ∀x∈[a,b],ϕ(x)∈[a,b];
- ∀x∈[a,b],∣ϕ′(x)∣≤L<1。
则:
- x=ϕ(x)在[a,b]有唯一根s;
- xk→s;
- ∣s−xk∣≤1−LLk∣x1−x0∣
- ∣s−xk∣≤1−LL∣xk−xk−1∣
可以压缩这个[a,b]区间,得到定理:s=ϕ(s),ϕ′(x)在包含s的某个开区间内连续。如果∣ϕ′(s)∣<1,则存在δ>0,当x0∈[s−δ,s+δ]时,由简单迭代法产生的序列 xk→s。
简单迭代法的收敛速度
若:
k→∞lim∣ek∣k∣ek+1∣=c
则称xk是$r $阶收敛的。
简单迭代法是r阶收敛的。
定理:若在ϕ(m)(x)在包含s的某个开区间内连续,如果
ϕ(i)(s)=0(i<m)ϕ(m)(s)=0
则简单迭代法以m阶速度收敛于s。
牛顿法
ϕ(x)=x−f′(x)f(x)
定理:f(s)=0,f′(s)=0,f′′(x)=0,那么∃δ,使得
{x0∈[s−δ,s+δ]xk+1=xk−f′(x)f(x)
二阶收敛到s。
下面这个定理给出一个更大的收敛区间:当下列条件满足时:
- f(a)f(b)<0;
- f′′(x)在区间[a,b]上不变号;
- x∈[a,b],f′(x)=0;
- x0∈[a,b],f(x0)f′′(x0)>0。
则由牛顿法产生的序列xk单调收敛于根,并且是平方收敛的。
五、插值与逼近
插值多项式
拉格朗日多项式:
f(x)=i=1∑nyili(x),其中li(x)=∏j=1,j=inxi−xjx−xj。
牛顿多项式:
.差商:f[x0,x1]=x1−x0f(x1)−f(x0),更一般地,k阶差商:f[x0,x1,⋯,xk]=xk−xk−1f[x0,x1,⋯,xk−2,xk]−f[x0,x1,⋯,xk−2,xk−1],打乱顺序不影响差商的值。
牛顿插值多项式为:
Pn(x)=f(x0)+f[x0,x1](x−x0)+f[x0,x1,x2](x−x0)(x−x1)+⋯+f[x0,x1,⋯,xn](x−x0)(x−x1)⋯(x−xn−1)
误差分析
牛顿插值公式(拉格朗日插值公式)的余项为:
Rn(x)=(n+1)!f(n+1)(ζ)ωn+1(x)ωn+1(x)=i=0∏n(x−xi)
差商与原函数的关系
f[x0,x1,⋯,xn]=(n+1)!f(n+1)(ζ)
正交多项式系
函数的内积:
(f,g)=∫abρ(x)f(x)g(x)dx
若两个函数内积为零(如上式),则成f,g在[a,b]上带权ρ(x)正交。
正交多项式系的转化:将{ϕ0,ϕ1,⋯,ϕk}转化为正交多项式系:
Φ0(x)=Φ1(x)=Φ2(x)=Φi(x)=ϕ0(x)ϕ1(x)ϕ2(x)ϕi(x)−(Φ0,Φ0)(ϕ1,Φ0)Φ0(x)−(Φ0,Φ0)(ϕ2,Φ0)Φ0(x)−j=0∑i−1(Φj,Φj)(ϕi,Φj)Φj(x)−(Φ1,Φ1)(ϕ2,Φ1)Φ1(x)
最佳平方逼近
内积的的四个性质:可交换性、线性、可分可加性、非负性。
最佳平方逼近希望解决的问题是,使用简单函数p(x)去逼近f(x),其中p(x)是从子空间Hn=Span{ϕ1,ϕ2,⋯,ϕn}中的函数线性组合成的,找到的这个p∗(x)s是最佳平方逼近元素。
定理:p∗(x)是最佳平方逼近元素时的充分必要条件是:(f−p∗,ϕi)=0。
这个定理可以从三维向量空间的几何直观去理解。
六、数值积分
代数精度
∫abf(x)dx≈k=0∑nλkf(xk)
当f(x)为任何次数不高于m的多项式时等式成立,而当f(x)为某个m+1次多项式时等式不成立,则乘该求积公式有m次代数精度。
插值型积分公式
∫abf(x)dx≈k=0∑nλk(n)f(x)λk(n)=∫ablk(x)dx
其截断误差为:
Rn=∫ab(n+1)!f(n+1)(ξ)j=0∏n(x−xj)dx
定理:n+1个节点的插值型求积公式至少有n次代数精度。
定理:如果n+1个节点的求积公式有大于等于n次的代数精度,则该公式为插值型求积公式。
梯形积分
∫abf(x)dx≈2b−a[f(a)+f(b)]
其截断误差为:
R1=−12(b−a)3f′′(η), η∈(a,b)
梯形公式具有一次代数精度。
Simpson积分
∫abf(x)dx≈6b−a[f(a)+4f(2a+b)+f(b)]
其截断误差为:
R2=−2880(b−a)5f(4)(η)
Simpson积分有3次代数精度。
高斯型积分公式
高斯型积分公式是试图手动确定节点的位置,来实现更高的代数精度。
定理:求积公式是高斯型求积公式的充分必要条件是它的求积节点是n次正交多项式gn(x)的n个零点。(注意带权函数)
求积系数为 Ai=∫abρ(x)li(x)dx。
截断误差为:
R=an2(2n)!f(2n)(η)∫abρ(x)gn2(x)dx
故其代数精度为2n−1。
七、常微分方程初值问题解法
初值问题
{y′=f(t,y)y(t0)=y0
求上述y(x)表达式的问题即为初值问题。
李普希兹条件:∀u1,u2,∣f(t,u1)−f(t,u2)∣≤L∣u1−u2∣。
若李普希兹条件成立,则该初值问题有解且唯一。
显式单步法(欧拉法)
显式单步法的一般形式是:
y0=y(x0)yn+1=yn+hf(tn,yn)
隐式欧拉法
y0=y(x0)yn+1=yn+hf(tn+1,yn+1)
两步欧拉
yn+1=yn−1+2hf(xn,yn)
梯形公式
yn+1=yn+2h[f(xn,yn)+f(xn+1,yn+1)]
梯形公式法可以看成显式、隐式欧拉法的平均,该方法本质还是隐式的。
改进欧拉法
先用显式欧拉法对yn+1进行预测,算出yˉn+1=yn+hf(xn,yn)。
再将这个预测值带入隐式的梯形公式:
yn+1=yn+2h[f(xn,yn)+f(xn+1,yˉn+1)]
另一种表达为:
yp=yn+hf(xn,yn)yc=yn+hf(xn+1,yp)yn+1=21(yp+yc)
该方法也称为预估-校正法。
截断误差
初值问题单步法的一般形式为:
yn+1=yn+hϕ(xn,yn,yn+1,h)
整体截断误差为:ϵn=y(xn)−yn,实际上yn=yn−1+hϕ(xn,yn−1,yn,h)中,yn−1,yn是会逐步影响后序解的,所以一般使用局部截断误差R=y(xn)−[y(xn−1)+hϕ(xn−1,y(xn−1),y(xn),h)],将yn暂时认为是精确值。
局部截断误差比较
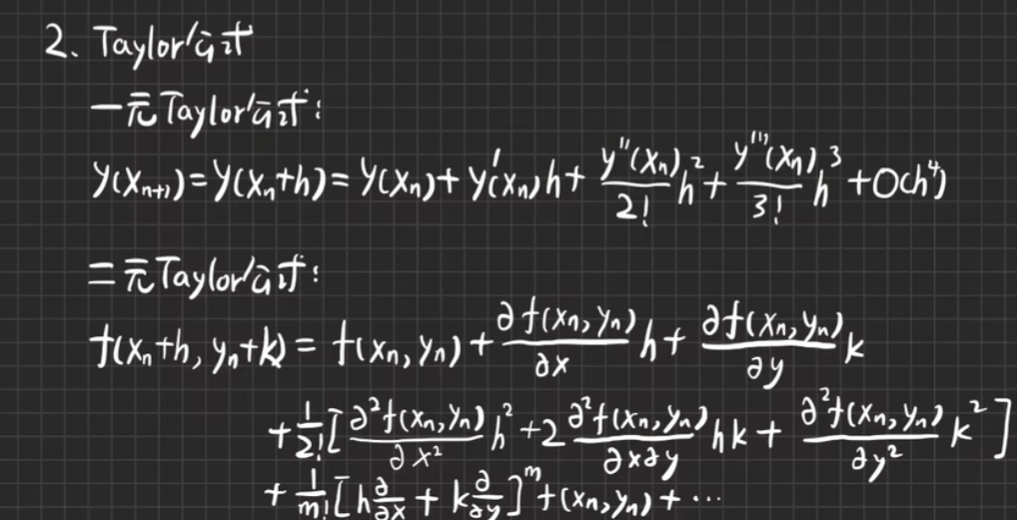
- 显式欧拉法:R=2h2y′′(xn)+o(h3)(一阶方法)
- 隐式欧拉法:R=−2h2y′′(xn)+o(h3)(一阶方法)
- 梯形公式法:R=−2h3y′′′(xn)+o(h4)(二阶方法)
计算截断误差阶数的方法:将R=y(xn)−[y(xn−1)+hϕ(xn−1,y(xn−1),y(xn),h)]的方括号里的项运用二元泰勒公式,再对y(xn)运用一元泰勒公式,比较其对应的项。
精度
若单步差分公式的局部 截断误差为o(hp+1),则该公式为 p阶方法。
方法的分析
相容性
相容性是指:
h→0limϕ(t,y(t),h)=f(t,y(t))
成立。
如果增量函数ϕ(t,y,h)连续,且对变量h满足李普希兹条件,则单步法与微分方程相容的充分必要条件是单步法至少是一阶的方法。
收敛性
如果下式成立
h→0limyn=y(t)
则称单步法为收敛的。或通过整体截断误差:
h→0limϵn=0
上述两式是等价的。
定理:如果增量函数ϕ(t,y,h)连续,并对变量y和h满足李普希兹条件,且单步法与微分方程形容,则单步法是收敛的。
绝对稳定性
绝对稳定性是指当初值有误差e0时,后续的误差将收敛到0:
n→∞limen=0
考虑绝对稳定性时,一般只考虑如下的线性常系数微分方程:
y′=λy
在计算绝对稳定性时,首先得到迭代格式。尝试展开迭代格式,然后将y′=f(t,y)代入,再将y′=λy代入,则可以得到yn+1=Φ(h,λ)yn,求解∣Φ(h,λ)∣<1这个不等式即可。
以二级二阶R-K公式为例,其迭代格式如下:
⎩⎪⎪⎨⎪⎪⎧yn+1=yn+2h(k1+k2)k1=f(tn,yn)k2=f(tn+h,yn+hk1)
可以先将k1,k2用yn表达出来:
k1=f(tn,yn)=y′(tn)=λy(tn)=λynk2=f(tn+h,yn+hk1)=y′(tn+1)=λy(tn+1)=λ(yn+hk1)=λ(yn+hλyn)
将k1,k2代入yn+1的表达式:
yn+1=yn+2h(λyn+λ(yn+hλyn))=(1+hλ+2(hλ)2)yn
同理,欧拉法求初值问题的公式为:
yn+1=(1+hλ)yn